Self Explore App part 1

Creating a windows app port for the web app fbexplorer
How to setup React with Electron
Setting up Electron
Quick start
Trying this Example
Clone and run the code in this tutorial by using the electron/electron-quick-start repository.
Note: Running this requires Git and npm.
# Clone the repository
$ git clone https://github.com/electron/electron-quick-start
# Go into the repository
$ cd electron-quick-start
# Install dependencies
$ npm install
# Run the app
$ npm startFor a list of boilerplates and tools to kick-start your development process, see the Boilerplates and CLIs documentation.
Questions
What does webpack — config webpack.common.js — watch do exactly?
What is a webpack?

How to get the media loading?
You need to set up the correct webpack loaders.
It would be best if you had a URL-loader for images
Use:
npm install url-loader --save
add to webpack configuration:
{
test: /\.(jpg|png|svg)$/,
use: {
loader: 'url-loader',
options: {
limit: 25000
}
}
},Great general electron guide
What is the difference between our old setup and the boilerplate?
- Where is the webpack config file?
- How did they get the index.html working on the src file folder?
npm install and yarn (install) are they the same, or do they cause any conflicts?
I like this inspiration for our corp website.

Why webpack matter?
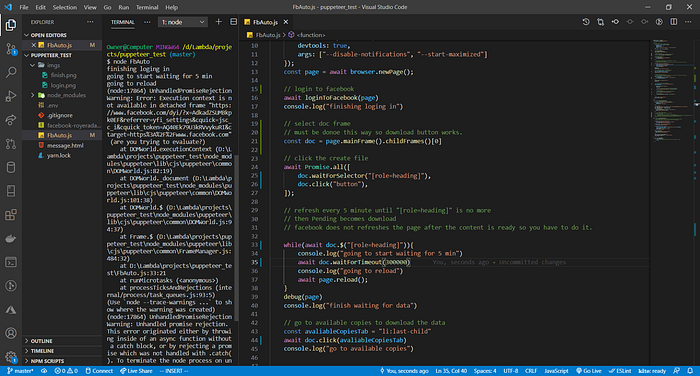
Puppeteer Automation
How to deal with Iframes?
Get access to the iframe, then go to the iframe link. Like this, you can have access to the iframe doc without having to deal with the nesting node elements. This is the simplest method.
The iframe content works like the embedded version.
How to set the path for the browser?
options: executablePath
Puppeteer iframe controls could be handle normally if they were targeting the correct iframe.
For example, this is how the main iframe is a handle. The main frame is the 1 layer node elements. Any other node element can be target by selecting the correct child frames and using the normal functions.
Download button does not work when using the direct iframe link for FaceBook
page.mainFrame().$(selector)fix it by using doc instead of page
const doc = page.mainFrame().childFrames()[0]Puppeteer wait for the file to download before you close up
Wait for the watching function to notice that the download file is finished.
- page.waitFor(selectorOrFunctionOrTimeout[, options[, …args]])
- fs.watch(filename[, options][, listener]) mention by StackOverflow.
fs.watch caveat, does not work properly with Linux.
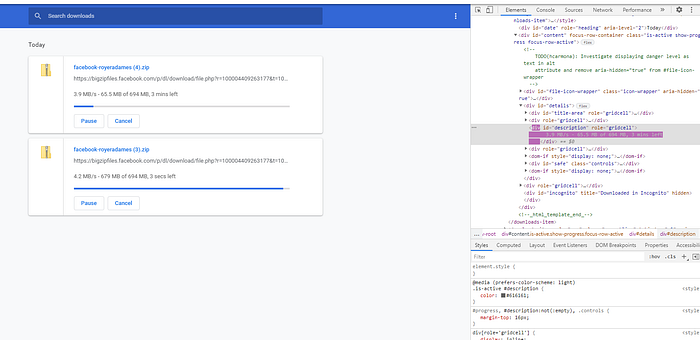
Downloading your data can take an arbitrage amount of time.
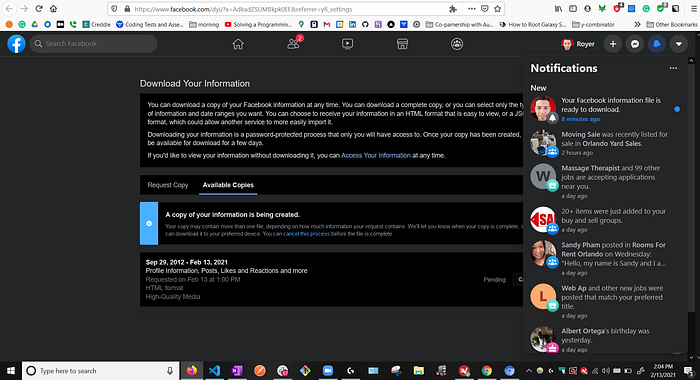
- My download time has ranged from 15 to 56 minutes.
- Facebook does not expect you to wait on that page.
They expect you to come back after they notify you.
- The page has to be a refresh for the notice of copy of the information to go away and a download button to appear

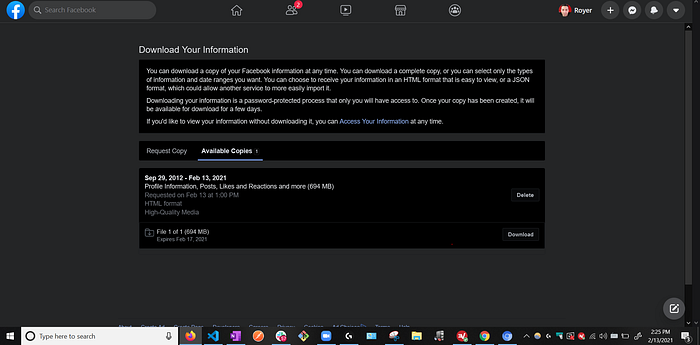
Reload the page every 5 minutes until you see the copy of the information notice disappear.
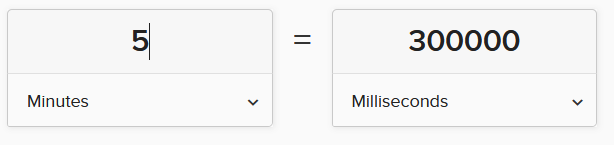
page.reload([options])
page.$(selector)
while you can see the [role=heading] reload for 300,000 miliseconds.
Sometimes you have to renter your password.
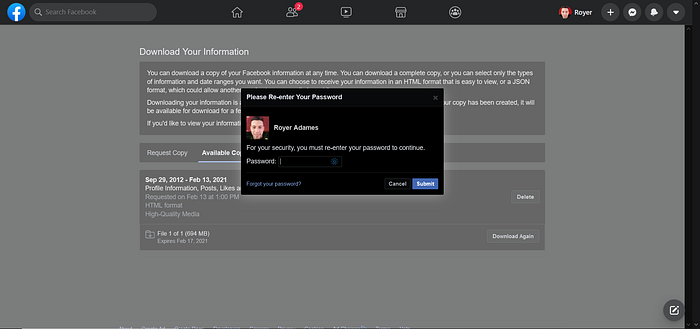
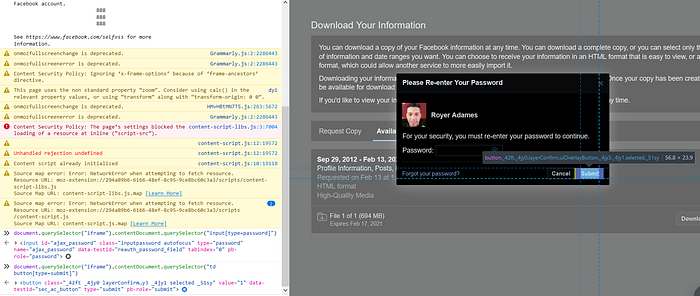
- input password element = input[type=password]

- submit button = td button[type=submit]
Document Waiting time varies.
The waiting script works properly.
Unexpected error
getting error UnhandledPromiseRejectionWarning: Error: Execution context is not available in detached frame. Are you traing to evalute?
A workaround is to open another browser and select the frame and then its content.
- Don’t refresh
- Don’t go to another page.
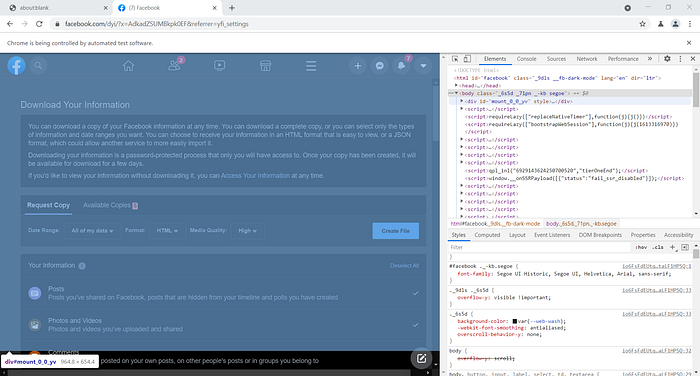
When I reloaded the page, the iframe became detach.
// reattach frameelementHandle = await page.$('iframe');doc = await elementHandle.contentFrame();
You can solve this issue by reattaching the child frame to the parent frame right after reload.
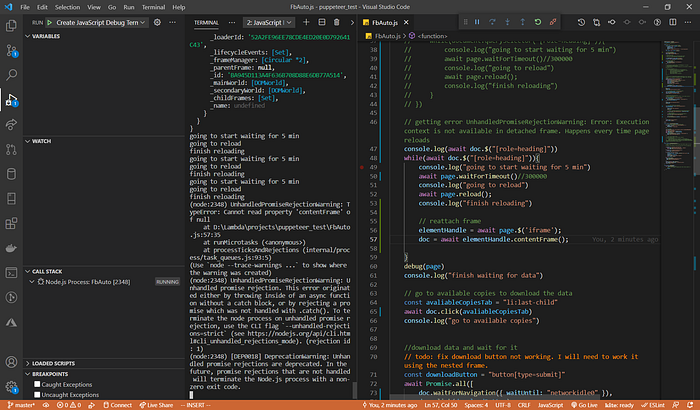
The solution does not work consistently.
Leads
- https://stackoverflow.com/questions/50242653/how-does-an-elementhandle-differ-from-a-dom-element
- https://pptr.dev/#?product=Puppeteer&version=v7.1.0&show=api-class-frame
- https://pptr.dev/#?product=Puppeteer&version=v7.1.0&show=api-class-elementhandle
- https://pptr.dev/#?product=Puppeteer&version=v7.1.0&show=api-overview
The frame issues are being caused because of unsupported HTML 4 implementation.
On funder research:
The HTML frameset and frame elements were used to create page layouts in which certain content remained visible while other content was scrollable. Using frames is primarily about creating a specific look and layout, a presentation task that should really be handled with CSS.
If you have a website that uses frames, you should start planning a website migration away from frames. At some point in the future, support for frames will be dropped by modern web browsers, and when that happens, websites build with frames will become unusable.
Increase understanding of the problem:
Selecting the iframe dom element = ElementHandle
ElementHandle prevents DOM elements from garbage collection unless the handle is disposed of. ElementHandles are auto-disposed when their origin frame gets navigated.
When I refresh the page or go to the same page, the iframe content frame breaks.
Doc when working
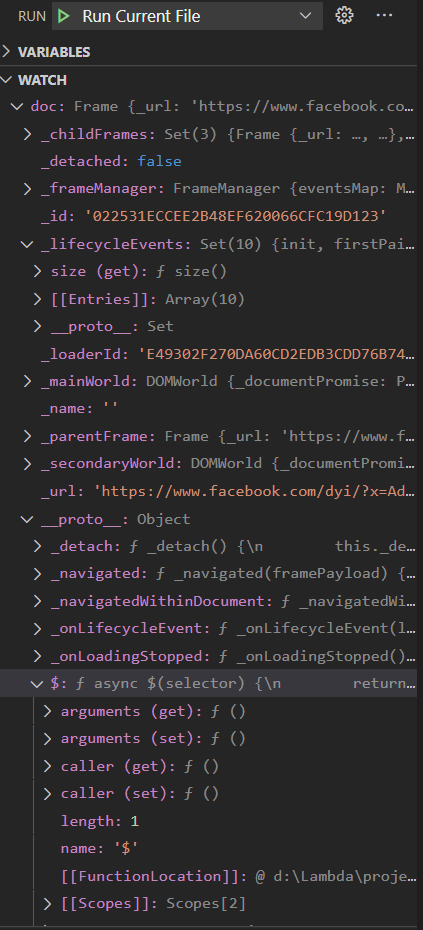
Doc when it stops working

Change download folder path with puppeteer env variable
https://pptr.dev/#?product=Puppeteer&version=v7.1.0&show=api-environment-variables
PUPPETEER_DOWNLOAD_PATH - overwrite the path for the downloads folder. Defaults to <root>/.local-chromium, where <root> is puppeteer's package root.
Not working
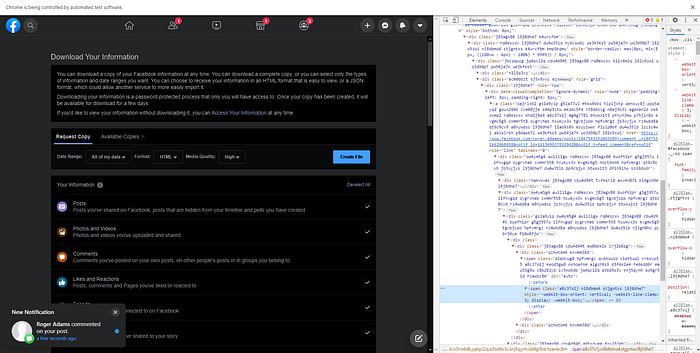
Get the notification notice, then download the data.
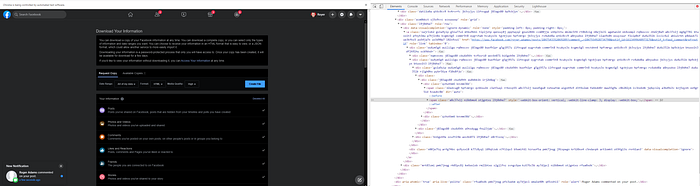
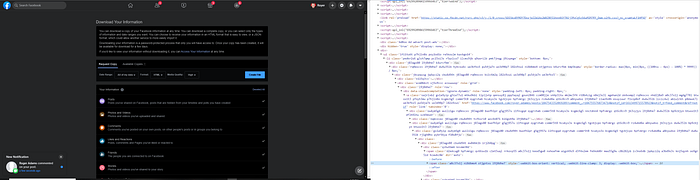
Error: after successfully waiting for the data to be ready when to select the iframe and had no content node.
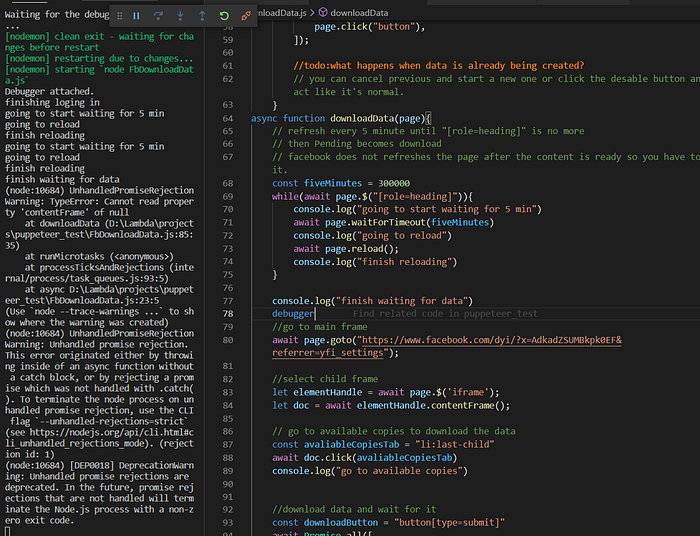
UnhandledPromiseRejectionWarning: TypeError: Cannot read property ‘contentFrame’ of nullWhy the fail download errors?
It didn’t use to do that.
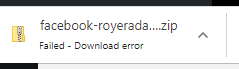
Because of this code:
// set download location to local project pathawait page._client.send("Page.setDownloadBehavior", {behavior: "allow",downloadPath: "./downloads",});
ContentFrame is not found when moving from the iframe to the mainframe.
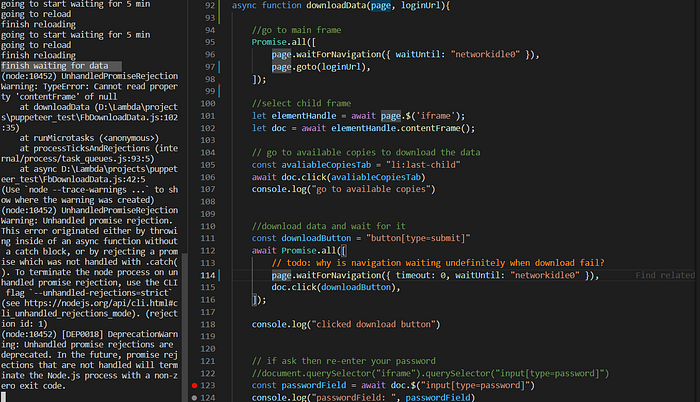
I can overcome this by creating a new page for the download script.
Error: The script does not continue after the download is finish
Workaround it to download again, and the file continues to download. If you let it stay idle you get a network error.

The download stops, and if you let it stay idle, you get a network error.
Workaround is to download again, and the file continues to download.

v1 assumes that download will be a success