Self Explore App part 2
Possible solution: change the download path from the google settings.’
Remember to scape your string and have it based on your drive.
D:\\Lambda\\projects\\puppeteer_test\\dataD:\\Lambda\\projects\\puppeteer_test\\data
The script will make the folder if the folder does not exist.
The puppeteer way
const downloadBrowser = await puppeteer.launch({env: {PUPPETEER_DOWNLOAD_PATH: "D:\\Lambda\\projects\\puppeteer_test"}});
The bound to change the way
// set download location to local project pathawait page._client.send("Page.setDownloadBehavior", {behavior: "allow",downloadPath: "D:\\Lambda\\projects\\puppeteer_test",});
The custom way
chrome://settings/downloads

Change button

document.querySelector("settings-ui").shadowRoot.querySelector("#main").shadowRoot.querySelector("settings-basic-page").shadowRoot.querySelector("[section='downloads']").querySelector("settings-downloads-page").shadowRoot.querySelector("#changeDownloadsPath")Change location

- select file path
- paste desire path
D:\Lambda\projects\puppeteer_test- click select path
I can do all of this in another tab before the download starts.
Can create a custom wait for file download when working with the chrome download page.
chrome://downloads/
- I can wait for 1 sec and until the download progress bar stops.
- If the download reaches 0 and (download MD is not equal to total MB or 0 seconds left), I download a file again, and in 3 seconds, I cancel it.


Progress bar

document.querySelector("downloads-manager").shadowRoot.querySelector("#mainContainer").querySelector("#downloadsList").querySelector("downloads-item").shadowRoot.querySelector("#details").querySelector("#progress")Not so fast. The div goes invisible.

You can still find the document here. I have to find the parent div of #progress and notice the style of display none.


This could work
$('li[style*="display: none"]')Working code:
document.querySelector("downloads-manager").shadowRoot.querySelector("#mainContainer").querySelector("#downloadsList").querySelector("downloads-item").shadowRoot.querySelector("#details div:nth-child(4)[style*='display: none']").hiddenNote:
- when it finishes downloading, the download speed stays at 0 for 2–3 seconds.


Suppose it fails to download because of lack of space. Then it downloads again.

Select the element with the shadow tree without having to use the shadow root method.
What is Shadow DOM?

https://stenciljs.com/docs/end-to-end-testing#find-an-element-in-the-shadow-dom
part A space-separated list of the part names of the element. Part names allow CSS to select and style specific elements in a shadow tree via the ::part pseudo-element.

I cannot use it because the part needs to be set.
The: host pseudo-class, when evaluated in the context of a shadow tree, matches the shadow tree’s shadow host. In any other context, it matches nothing.
The :host() function pseudo-class has the syntax:
:host( <compound-selector> )The using host got me null values.

A workaround could be to use the page.evaluateHandle to target the DOM element.


page.waitForSelector(selector[, options])

There is no selector option. I cannot use this when evaluating.
await settingPage.waitForNavigation({ timeout: 0, waitUntil: "networkidle0"})Waits indefinitely or until time out.

setTimeout()
best to clearTimeout() when done using the timeout.
Remember to catch id by setting the setTimeout to a variable
do…while
setInterval()
have to use ClearInterval to stop the repeat of the code or unscoped it.
Remember to catch id by setting the setInterval() to a variable
await
try…catch
Optimization hints
- It takes 52 sec to 1 minute for the download to timeout.
- Is there a setInterval like the function that can wait for an event to be fire? Maybe a chrome dev tools event listener breakpoints that I can use with puppeteer that lets me know when a file is downloading, stop downloading, and finish downloading.
Progress so far

Custom file waiter is working.
- It needs a way to deal with a Facebook network error.
- It can be optimized by making the code wait for downloading of the file to be finished.
- It needs to be tested with the other scrips.
Success


Need to do before moving to electron integration
- does it work headless?
- Network issues need to be solved automatically.
Network issues need to be solved automatically.
Cancel button

document.querySelector("downloads-manager").shadowRoot.querySelector("#mainContainer").querySelector("#downloadsList").querySelector("downloads-item").shadowRoot.querySelector("#details").querySelector("#safe").querySelectorAll("cr-button")[1]Picking a download folder

They are ordered by row index. The newest will always be number 1, and the oldest will be the total of all download files. This example is 3. The example below shows how to select the 2nd downloaded folder.
document.querySelector("downloads-manager").shadowRoot.querySelector("#mainContainer").querySelector("#downloadsList").querySelector("downloads-item[aria-rowindex='2']")Remove option

document.querySelector("downloads-manager").shadowRoot.querySelector("#mainContainer").querySelector("#downloadsList").querySelector("downloads-item").shadowRoot.querySelector("#remove")description

document.querySelector("downloads-manager").shadowRoot.querySelector("#mainContainer").querySelector("#downloadsList").querySelector("downloads-item").shadowRoot.querySelector("#details").querySelector("#description").innerText
"0 B/s - 248 MB of 694 MB, Paused"

Download speed
document.querySelector("downloads-manager").shadowRoot.querySelector("#mainContainer").querySelector("#downloadsList").querySelector("downloads-item").shadowRoot.querySelector("#details").querySelector("#description").innerText.split(" ")[0]"0"
Current Data
document.querySelector("downloads-manager").shadowRoot.querySelector("#mainContainer").querySelector("#downloadsList").querySelector("downloads-item").shadowRoot.querySelector("#details").querySelector("#description").innerText.split(" ")[3]"112"
Total data
document.querySelector("downloads-manager").shadowRoot.querySelector("#mainContainer").querySelector("#downloadsList").querySelector("downloads-item").shadowRoot.querySelector("#details").querySelector("#description").innerText.split(" ")[6]"694"
Conver the string to number
Number( )
Number(document.querySelector("downloads-manager").shadowRoot.querySelector("#mainContainer").querySelector("#downloadsList").querySelector("downloads-item").shadowRoot.querySelector("#details").querySelector("#description").innerText.split(" ")[3])The contrast of finish download description and still working on it



document.querySelector("downloads-manager").shadowRoot.querySelector("#mainContainer").querySelector("#downloadsList").querySelector("downloads-item").shadowRoot.querySelector("#details").querySelector("#description").hiddendocument.querySelector("downloads-manager").shadowRoot.querySelector("#mainContainer").querySelector("#downloadsList").querySelector("downloads-item").shadowRoot.querySelector("#details").querySelector("#description").hiddenInteresting
The Location.reload() method reloads the current URL, like the Refresh button.
JavaScript Date objects represent a single moment in time in a platform-independent format.

Date().split(" ")[4]Can you overwrite same name files in chromium?
Node Debugger does not work with Puppeteer evaluator
Solutions:
- wrap the evaluator DOM element into a variable and use puppeteer instead of the evaluator
- create a call back that loops around until a successful download of the file are made
- redownload the document on the Dev console
The document could be redownloaded by clicking the downloading URL

document.querySelector("downloads-manager").shadowRoot.querySelector("#mainContainer").querySelector("#downloadsList").querySelector("downloads-item").shadowRoot.querySelector("#details").querySelector("#url")Auto network fix is a success.

Start dev console the console tab.
No easy way to do so
Refactor the script
Get all functions into their own file
- loginToFacebook
- createData
- waitForData
- downloadData

New functions names
- loginToFacebook
- createFile
- waitForFile
- downloadFile

Others
research
const fs = require("fs");Twitter Data Archive Automation



Current Script Hierarchy

Testing for a breakthrough:
Fix frame detach
frame detachment could have been because when I reloaded the page, I didn’t wait for the frame to load its elements back up
Simplify waitForFileDownload
can be simplified the evaluation by using it to create a JSHandler of the variables and extract a boolean value.
- This opens up the reuse of start file download if they ask the user to reenter their credentials and takes away the custom waiting functions.
- Allows for console logs to be on the script instead of on the headless chromium-browser
Can we wait for navigation use load instead of waiting for all network activities to die down?
?
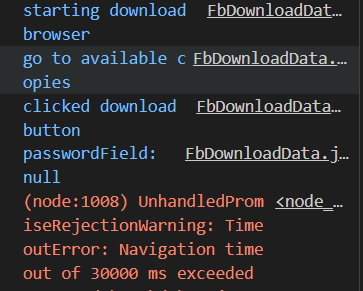
Puppeteer works fine in dev mode but breaks in headless mode.
Chrome download is not accessible in headless mode.

chrome://downloads/
chrome://downloads/ can be the part of the GUI that headless ( command line mode) does not load.
Solution: I need a command that updates me on the current download status
puppeteer github docs feels more complete than their website doc.
httpRequest.url()
- returns: <string> URL of the request.
httpRequest.headers()
- returns: <Object> An object with HTTP headers associated with the request. All header names are lower-case.
- MDN

Useful headers
- request URL
- Status Code
Where can I find the download speed?
page.waitForRequest(urlOrPredicate[, options])
- capture the request URL of the get 200 status
- wait for the request URL with a timeout of 0
Research and development
Playwright makes everything I want to do with Puppeteer easy period.
Wait for the file solution.
Handle authentication gracefully
The major component for fixing network error.
Useful yarn commands
yarn add <package...> [--dev/-D]
Using --dev or -D will install one or more packages in your devDependencies.
yarn run [script] [<args>]
Create React app on Yarn
yarn create <starter-kit-package> [<args>]
This command is a shorthand that helps you do two things at once:
- Install
create-<starter-kit-package>globally, or update the package to the latest version of it already exists - Run the executable located in the
binfield of the starter kit’spackage.json, forwarding any<args>to it
For example, yarn create react-app my-app is equivalent to:
$ yarn global add create-react-app
$ create-react-app my-appIf you have defined a scripts object in your package, this command will run the specified [script]. For example:
Start package.json
yarn init
This command walks you through an interactive session to create a package.json file. Some defaults such as the license and initial version are found in yarn’s init-* config settings.
Rebuilding Download file script on playWright
document.querySelector("iframe")Waiting for the iframe element

Sometimes Facebook adds a iframe on the login page
waiting for navigation load

waiting for navigation domcontentloaded
wait for navigation network idle

Console.log await download.createReadStream()

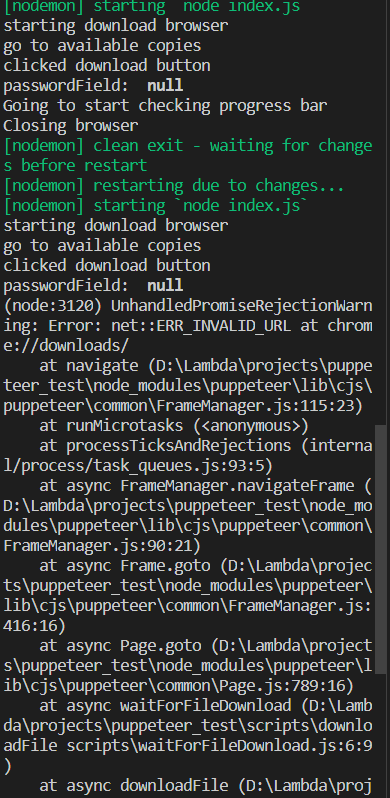
Error
[Error: EPERM: operation not permitted,
unlink 'C:\Users\Owner\AppData\Local\Temp\playwright_chromiumdev_profile-3XZLP0\CrashpadMetrics-active.pma'] {
errno: -4048,
code: 'EPERM',
syscall: 'unlink',
path: 'C:\\Users\\Owner\\AppData\\Local\\Temp\\playwright_chromiumdev_profile-3XZLP0\\CrashpadMetrics-active.pma'After some time, the network idle became like this.

How to change the name of a download file
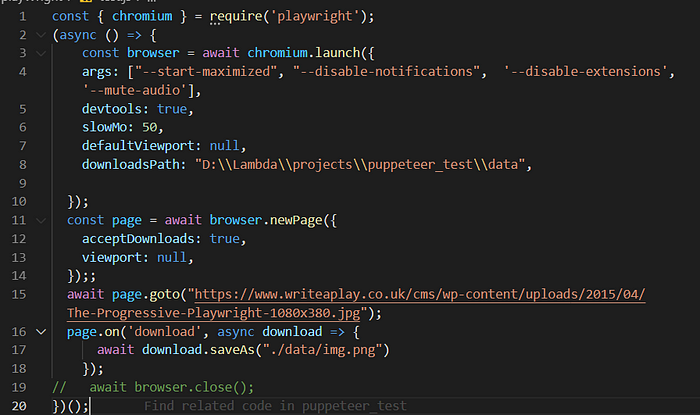
const { chromium } = require('playwright');(async () => {const browser = await chromium.launch({args: ["--start-maximized", "--disable-notifications", '--disable-extensions', '--mute-audio'],devtools: true,slowMo: 50,defaultViewport: null,downloadsPath: "D:\\Lambda\\projects\\puppeteer_test\\data",});const page = await browser.newPage({acceptDownloads: true,viewport: null,});;await page.goto("https://www.writeaplay.co.uk/cms/wp-content/uploads/2015/04/The-Progressive-Playwright-1080x380.jpg");page.on('download', async download => {await download.saveAs("./data/img.png")});// await browser.close();})();

The problem is that it 2 downloads.
Solution
page.on('download', download => {
// save the download file has the suggested file namedownload.saveAs(`./data/${ download.suggestedFilename()}`)// delete the criptic file name
download.delete()});
If the same file is redownloaded it will be overwritten.
Weir behavior recorded
I notice that it didn’t work for the first 3 downloads for a large image, but after that, it did. Also, it works for videos, and it works fine.
Error: EPERM: operation not permitted, unlink
[Error: EPERM: operation not permitted, unlink 'C:\Users\Owner\AppData\Local\Temp\playwright_chromiumdev_profile-lE48xW\CrashpadMetrics-active.pma'] {
errno: -4048,
code: 'EPERM',
syscall: 'unlink',
path: 'C:\\Users\\Owner\\AppData\\Local\\Temp\\playwright_chromiumdev_profile-lE48xW\\CrashpadMetrics-active.pma'
}To solve it, you have to:
1) add your project folder to the Windows Defender exclusions list.
2) remove your node_modules folder
3) run:
npm installHow can I tell the user how to progress is going?
- What time it started downloading.
- Current download speed
- Current data — Max data — current time
I don’t know how to get the above live data, but I can do an interval console.log for every 1/2 a minute to say that it is being downloaded.
1/2 a minute download reports

Downloading more than 1 file will keep the report coming until the program is stop
setInterval()

Things to do
- Network fix needs to be implemented
- File report bug needs fixing
Downloading more than 1 file will keep the report coming until the program is stop
— Move the whole scrip to Playwright
- Add Reuse authentication state solution
Convert Puppeteer scripts to Playwright
Issue


That said, it still works on dev tools.



Solution

The error was due to all files expiring. The solution is to get a new file.
Polishing and debugging script for v1 integration
handle the case when the get file button is disabled

document.querySelector("iframe").contentDocument.querySelector("button[aria-disabled='false'")
The cancel button also appears, so I need a more specific identifier path.
$x("//button//div[text()='Create File']/../..")[0]

When the button should have been true, it was false. Does this mean that the doc var data is a snipe of a previous state?

Frame detaching after reloading the page

Solution for download issues
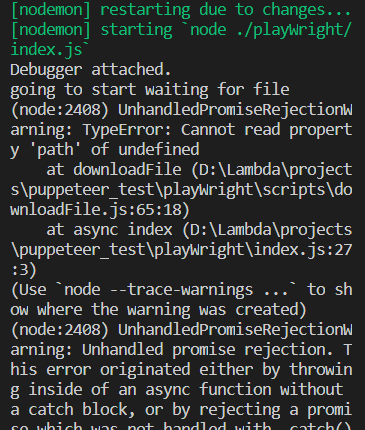
Error

Solution

Speed up wait for download event to fail
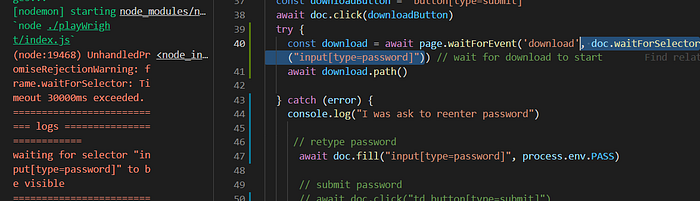
I will need to wait for the input selector to fail then wait until the event time out
even with the error, the script continues and stops after the file has been downloaded.

Why do I have a bunch of chromium tasks running when the browser is closing correctly?

Possible cause: When the scrip fails and it does not get to browser.close it still takes CPU resources. Only in headful mode
Error: fill(“input[type=password]”) timeout

The download button broke. You click it, and nothing happens. No download or anything, but if you reload the page, it works again.
Error: not constant error

use this for Twitter
Moving to electron integration.
A button that runs a script
- script tag
- on click event
